git: Using Advanced Rebase Features for a Clean Repository
Recently I have prepared a video about advanced rebased features and how we can use them to make our git repository clean.
The video explains basic usages along with advanced features, in this blog post I will refine the rationale behind the clean repository.
Git is a very powerful tool. It can be used to solve hard problems encountered during the development. However, we tend to use a small subset of its features. It’s not a new tool anymore, its features are not new, it’s around since 2006 now.

Anyways, I will focus on the repository, git history, and talk about how we can (and I do) keep the history clean.
Rationale
A git repository is where our code stays with its history. Having historical information has lots of benefits. We can see what has changed, in which order changes are introduced, and who changed it clearly. Keeping the code history is a much like writing code. Martin Fowler said:
Any fool can write code that a computer can understand. Good programmers write code that humans can understand.
Like writing code, there is a good and a bad way of keeping the history. I think the same quote can be used for git history:
Any fool can make commits that a computer can understand. Good programmers make commits that humans can understand.
The Problem
Let’s see what happens when you don’t care about your repository’s history. This screenshot was taken from a four years old repository:
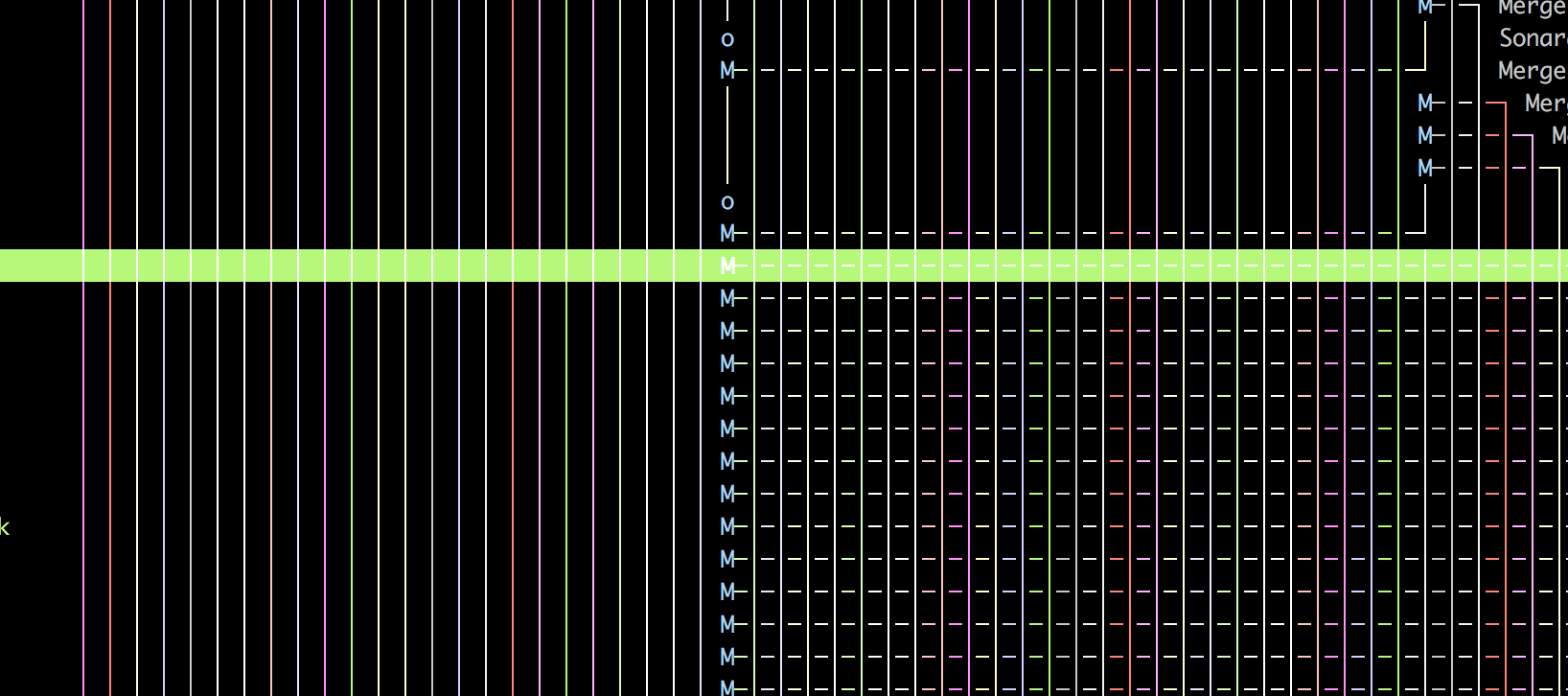
It’s impossible to understand what’s going on here. Well, one thing can be said: lots of merge commits. LOTS OF! Please don’t do this if you care about future developers.
The Solution
After struggling this for enough time, I have proposed a solution: Rebase. Use rebase. Pulling from remote branch? Pull with rebase. Your feature branch is behind master? Rebase your branch onto master. Do your commits not organized well? Rebase your branch with interactive mode and re-organize your commits. Then I have organized small sessions on how to use rebase features. The video is a result of those small sessions. The git history is now (mostly) as in the following screenshot:
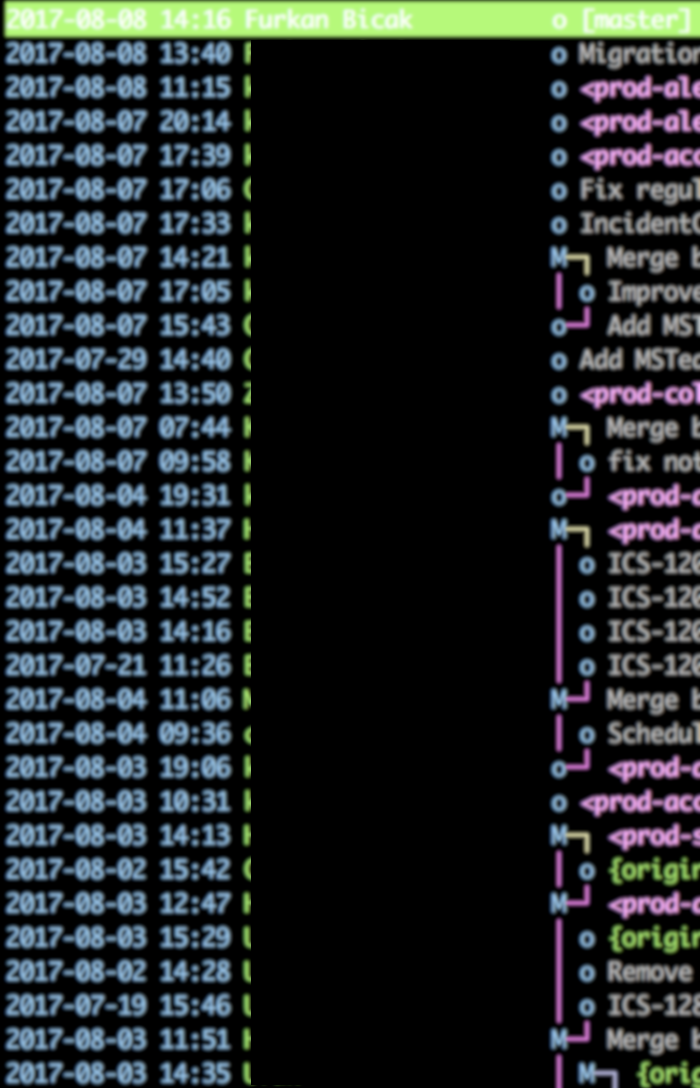
There are minimum merge commits. The order of changes can be tracked very easily. It’s elegant. It’s clean. Less is more, we got rid of unnecessary merge commits, there are less commits, the history is more visible.
Advanced rebase features
Now I want to talk about how we can refine commits at the time of rebase. Let’s assume we have a branch with following commits:
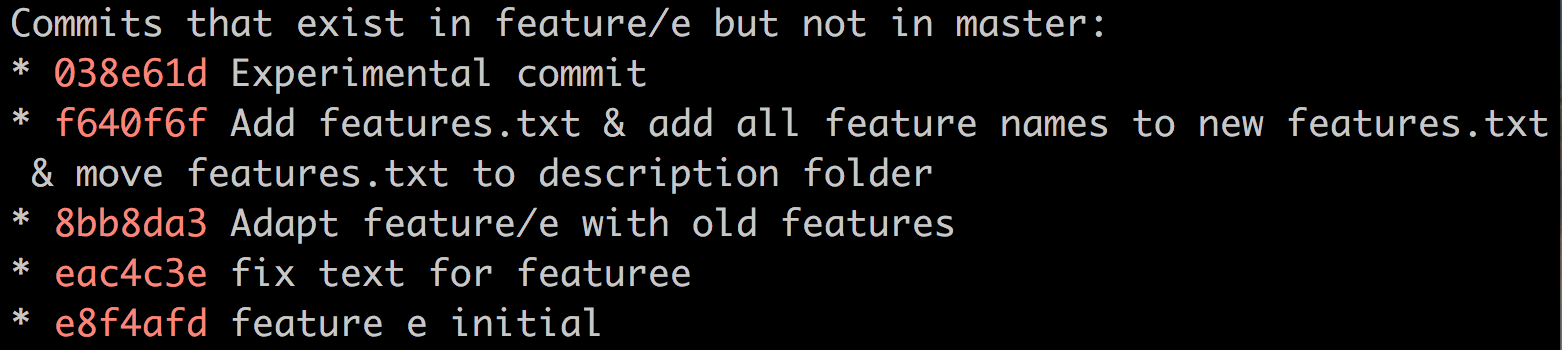
Let’s go over the problems one by one:
- First commit - feature e initial: Very bad commit message.
- Second commit - fix text for feature e: Extremely unnecessary commit. This commit fixes a problem in the first commit, it shouldn’t be in the history of the repository. Why would we like to keep something like this in our history? The changes of this second commit should be implemented in the first commit.
- Third commit: looks okay, but for the sake of the example I assume we need to edit something in this commit.
- Forth commit: Bad commit message. This commit message looks more like the body of the message. First line should be 50 characters at most, then an empty line comes, and the body can be as long as we want.
- Fifth commit - experimental? What does it even do in the branch? It should be removed.
Now, let’s see interactive rebase screen for this branch. I run the following command (this is a feature branch so it can be rebased onto master):
$ git rebase -i master
This is the interactive rebase screen:
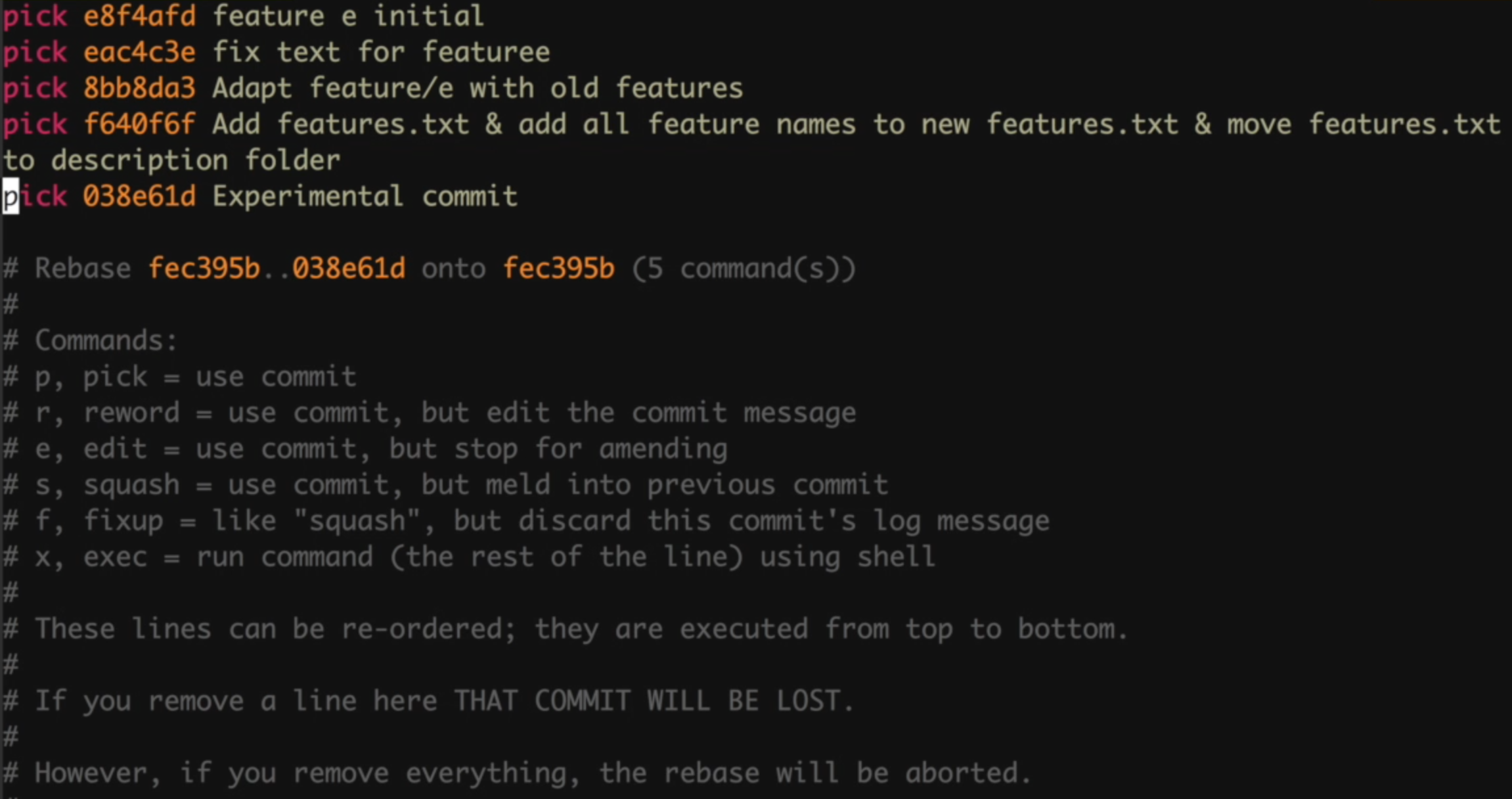
The explanations in the comments are enough to understand what to do here. Other than comments, we have commands, commit revision numbers, and commit messages. Commands will be applied to the commits with respect to their revision number. The commit messages for us humans to understand which commit the revision number corresponds to, if we edit the message in this screen, git won’t change the commit messages. The order of commands are important, because git will follow this order. If we reverse the order in this screen, last commit will become the first and first commit will become the last.
So, to fix the problems I have mentioned above, I have prepared the commands like this:
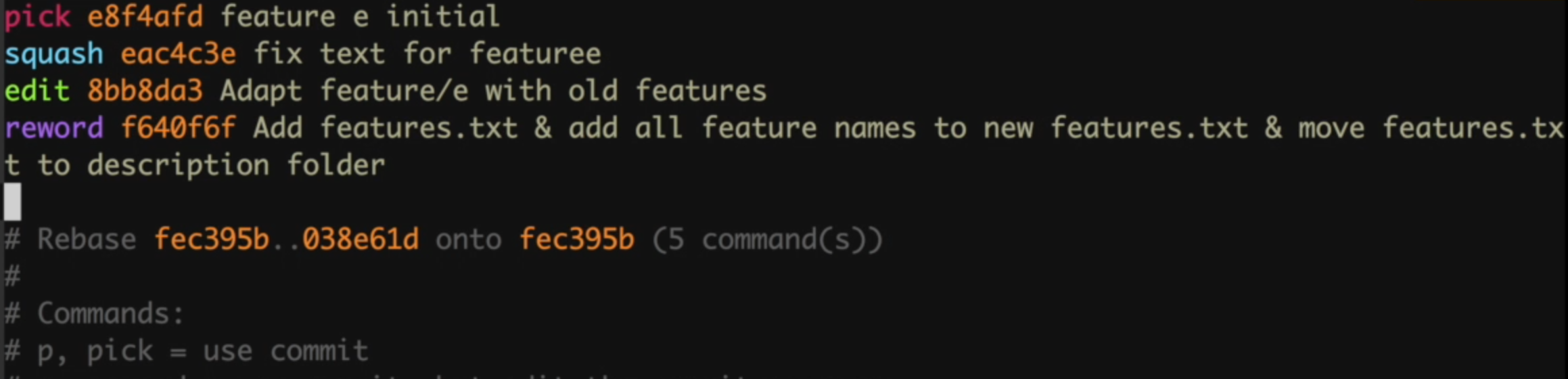
- We are picking the first commit, because we are squashing the second commit into this one we don’t need to say reword to change the commit message. Git will ask us a commit message for the combined commit.
- We are squashing this unnecessary commit into the previous one. As I said, the commit fixes a problem in previous commit and the changes here should have been in the first commit from the beginning.
- We would like to edit something in this commit. Git will stop rebasing while applying this commit to allow us make the necessary changes.
- We can change this commit’s message with reword command. Again git will ask us the new commit message while applying rebase.
- I have deleted the line for experimental commit, so it will be removed from branch’s history.
After rebase finishes successfully, our branch looks like this:

First commit’s message could be better, but this version is much better than the previous history. extra commits are gone, commit messages are better. I have even deleted a commit from the history.
You can watch the video above for sample use-cases of rebase: with local branch, remote tracking branch, conflicting branch, branch with multiple commits, and rebase with interactive mode.
All in all, your history is important. Stay clean, stay sane.
Some resources:
- How to Write a Commit Message: https://chris.beams.io/posts/git-commit/
- Feature branching: https://www.atlassian.com/git/tutorials/comparing-workflows#feature-branch-workflow
- Merging vs Rebasing: https://www.atlassian.com/git/tutorials/merging-vs-rebasing
- Interesting Rebases: https://git-scm.com/book/en/v2/Git-Branching-Rebasing
UPDATE: Lots of discussion have been held about this post in Hacker News and Reddit, I suggest you to take a look at them for various opinions.