Getting Information from ECS Events
In Bayzat, we are using AWS ECS Fargate to manage production and development workflows. In our automation hustles, we are leveraging ECS events to get information about state changes of tasks and services. AWS documents explain how to get started handling ECS events clearly. In this blogpost, I’ll talk about how we use the events, what kind of information we can get out of them, and what we can’t.
Background
We are using exactly the same infrastructure resources and automation code for production and development environments with lower resource utilization. This means that testing environments are also deployed to Fargate containers as well as production. I believe it is important to identify problems quickly and spread the sense of how deployments work: tasks stop, tasks start, services change state, and so on. Therefore, we decided to stream ECS events to Slack channels for all environments.
ECS events are streamed to Lambda functions over EventBridge, where they are analyzed, formatted properly, and sent to Slack channels.
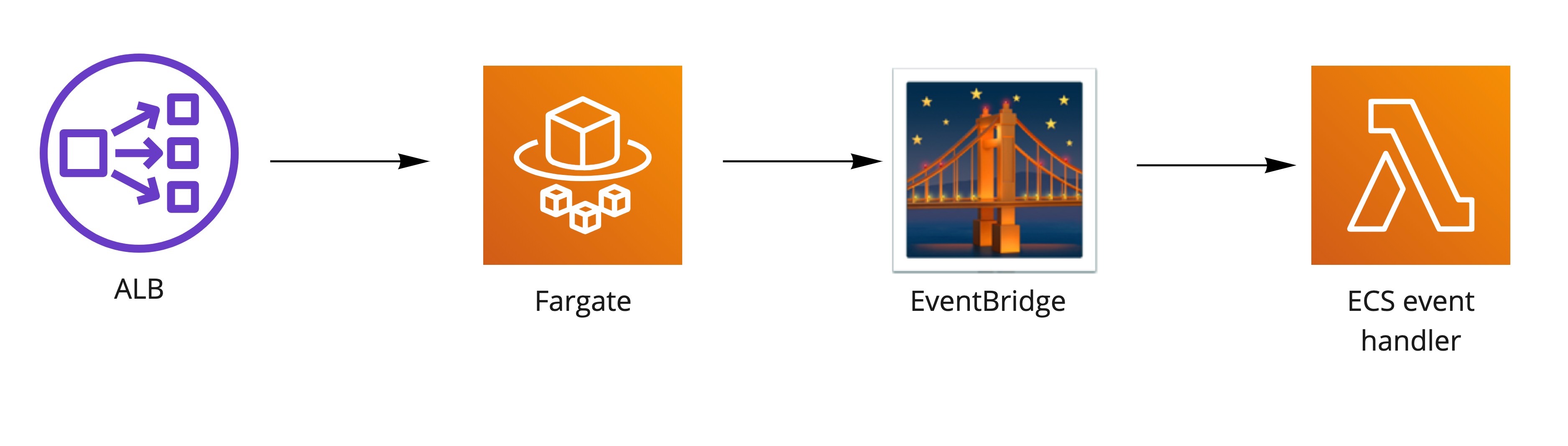
Event types
There are three ECS event types:
- Task state change events
- Service state change events
- Container instance state change events
Since we are using Fargate, only the first two types are meaningful for us. I’ll leave container instance state change events out of scope of this blogpost and to more capable hands.
Service state change events
The important thing about a service event is that when it reaches steady state. This means containers are started
properly, all health checks are passing, and the attached load balancer can access the service successfully. If there
was a deployment beforehand, deployment is successful when the service reaches steady. Also if your desired task
count is dynamic based on autoscaler rules, such as traffic or CPU/memory levels, then you’ll get
SERVICE_DESIRED_COUNT_UPDATED event.
Aside from reaching steady state, service events are fired when service can’t reach steady, or when there is a task placement error(not valid for Fargate).
While service events are important, they don’t contain much information. Task start impaired event is something like this:
{
"detail-type": "ECS Service Action",
...
...
"detail": {
"eventType": "WARN",
"eventName": "SERVICE_TASK_START_IMPAIRED",
"clusterArn": "arn:aws:ecs:us-west-2:111122223333:cluster/default",
"createdAt": "2019-11-19T19:55:38.725Z"
}
}
We’ll need more than this to understand the underlying problem. We need task state change events.
Task state change events
Task state changes events are the noisiest events in ECS events. We get an event for each state transition while the states are:
PROVISIONINGPENDINGACTIVATINGRUNNINGSTOPPINGDEPROVISIONINGSTOPPED
In a deployment, we get events for both old and new tasks as expected. There are LOTS of messages when the task is failing for some reason and it is not being addressed.
Task state change events also have a lot of information. They contain information about each container in the task, their last status, network interfaces, etc. In my opinion, here are some critical fields to take care in these events:
- Task ID: it is important to know which task we are talking about.
- Task created at: in the flow of events, it is easier to reason about a task with its creation timestamp instead of UUID.
- Desired status/last status: in a deployment, new tasks have
runningdesired status, and old tasks havestopping. Since the event also containslastStatusinformation, we comparedesiredStatusandlastStatusof the task to understand what state it is in. - Execution stopped at, stopping reason: These are crucial information for a stopping task. This field is where we
understand why the task is being stopped, is it because of a new deployment? Or the task can’t be started properly?
If you are using
FARGATE_SPOTcapacity providers, is your resource being taken away?
ECS events, overall, are similar to the Events tab in the service details in AWS Console, except the load balancer
registration events. As of course, they are quite limited compared to the full event details.
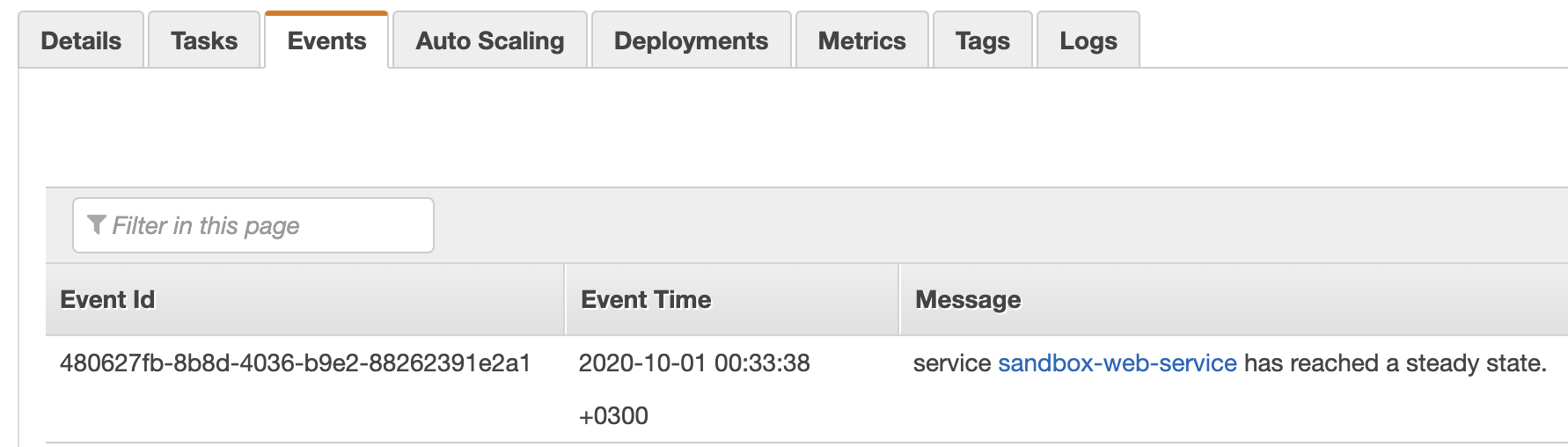
Posting to Slack
It is hard to post all the details of all events to the Slack. For the time being, we are handpicking some of the fields and posting them to a deployment tracking channel for the keen eyes, such as:
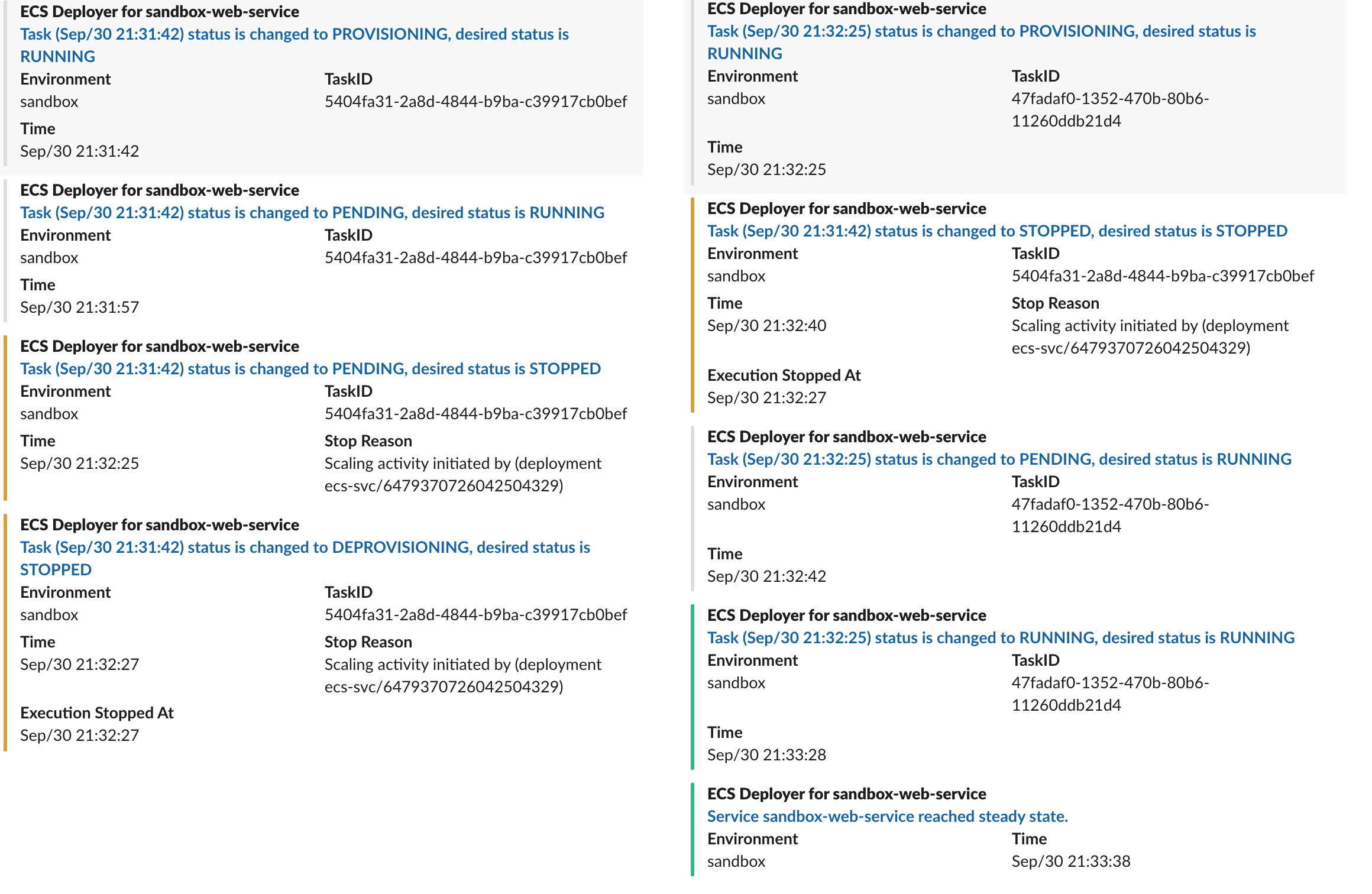
We aim to decrease the response time to an issue by leveraging these messages. They are posted in a matter of minutes, so it causes some noise in the channel.
Using events for automation
It is up to you to use these events as webhooks or triggers to do other things. It’s worth noting that blue/green deployment option in ECS has some Lambda function trigger support, which can be used to trigger automation workflows.
Potential improvements
- Along with ECS events, we are posting deployment start/finish messages to Slack too. When I have time, I’d like to make a connection between deployment triggers and ECS event messages; so that I can group the ECS event messages together with deployment start/finish messages.
- Right now, we know that a task can’t be started properly in case an error, as well as a service. The problem is, when there are numerous essential containers in a task, it is hard to identify which container is the culprit. The current event structure does not provide this information, but maybe we can retrieve the erroneous container from API.
- This is not on my hand, but we don’t receive load balancer task register events. Load balancer attaches to the task before the service reaches steady state, which means our service is available to load balancer traffic before it says it is steady. Knowing the difference would benefit us in decreasing the potential downtime or performance degradation, or identify some edge-case errors which make no sense in a fully boot-up server.